Part 8 of a series on giving AI coding agents shared organizational memory. Previously: Part 1 — Your AI coding agents have amnesia · Part 2 — I was measuring the wrong thing · Part 3 — No vector DB. No embeddings. No RAG. · Part 4 — Knowledge, not logs · Part 5 — /memorize and /recall · Part 6 — If you have
ghyou’re in · Part 7 — Two curators
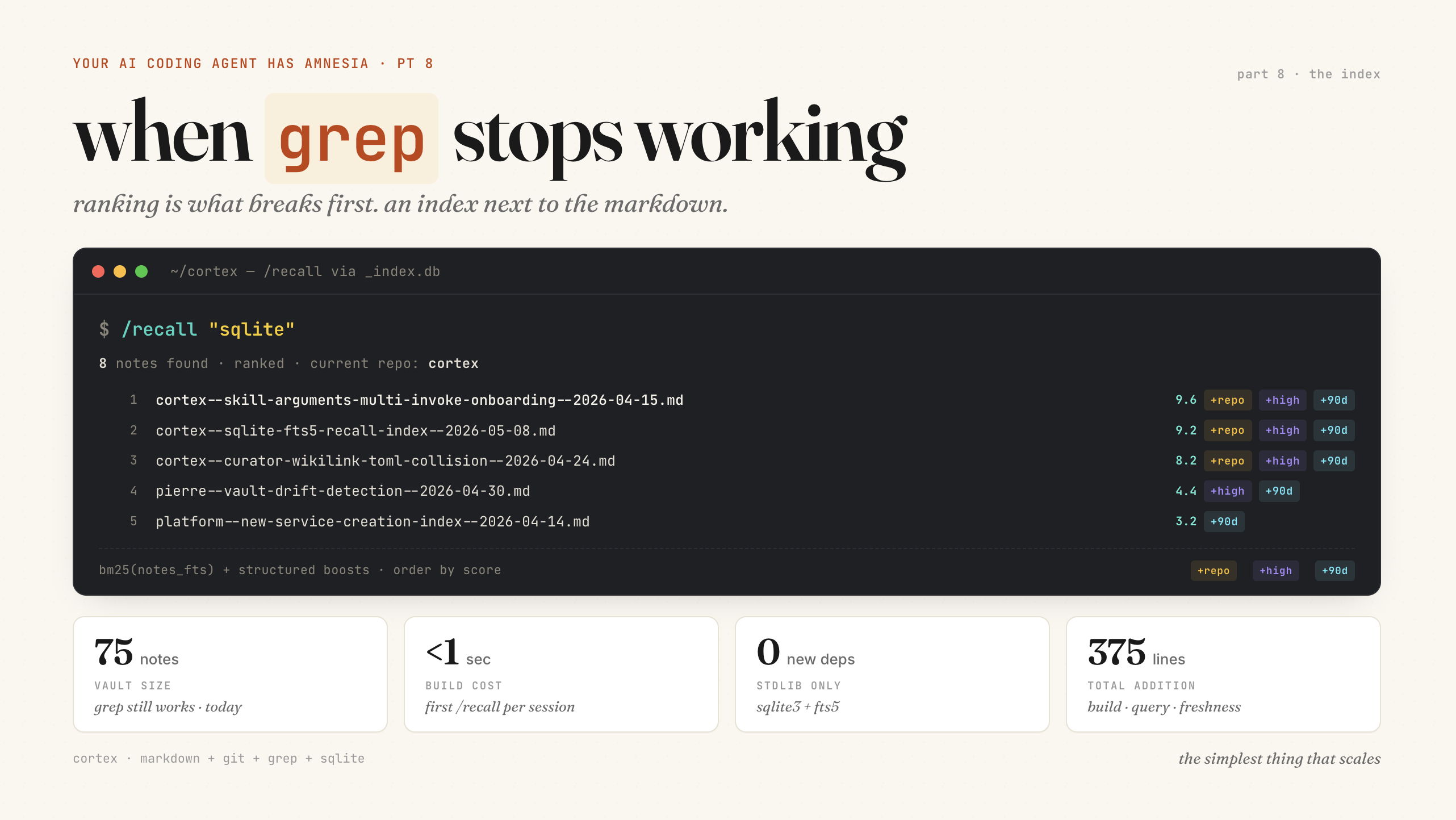
75 notes. Grep still works. Won’t for much longer.
The thing that breaks isn’t speed — grep is fast. It’s ranking. 4 hits in arbitrary order, you skim. 30 hits in arbitrary order, you don’t bother. Somewhere between here and 500 notes the experience flips from “useful” to “noise.”
So I added an index. _index.db — SQLite, sitting next to the markdown.
The change
About 375 lines of Python. Stdlib only — sqlite3 is in the standard library, FTS5 is built into SQLite. No new packages.
Two tables:
notes— one row per file, frontmatter as columns (repo,tags,date,confidence,services,files_touched)notes_fts— FTS5 over the body, BM25 ranked
Built on the first /recall of a session. Cached. Rebuilt when the vault’s HEAD SHA doesn’t match the SHA stamped in the index. Sub-second at this vault size. A couple seconds if it ever gets to 2000 notes.
Local-only. _index.db is gitignored. Vault is the source of truth, index is derived. If it ever corrupts, delete the file and the next /recall rebuilds it.
The query
/recall used to be three pipelined greps with hand-rolled ordering in bash. The index let me collapse all of that into one declarative query:
SELECT stem, title, repo, date, confidence,
bm25(notes_fts) AS score
FROM notes_fts JOIN notes USING (stem)
WHERE notes_fts MATCH ?
ORDER BY
score
+ CASE WHEN repo = ? THEN -2.0 ELSE 0 END -- current repo
+ CASE WHEN confidence = 'high' THEN -0.5 ELSE 0 END
+ CASE WHEN date > date('now','-90 days') THEN -0.3 ELSE 0 END
LIMIT 10Same priorities I was hand-rolling in bash before — repo, then confidence, then recency — just declared in one place now. BM25 does the relevance math I was approximating.
Grep stays as fallback. If the index build fails — corrupt .db, schema mismatch after a /recall upgrade, write-permission weirdness on the cache dir — /recall falls through to the old grep path and the user gets results, just unranked. Pure insurance.
First /recall on the new index, query sqlite. 8 hits. Top 3 sit at 9.6 / 9.2 / 8.2 — all cortex-repo notes, +repo lifting them. #4 drops to 4.4. Same recency, same confidence, no +repo. You can read the boost stack right off the score column.
What BM25 doesn’t do
BM25 is lexical. It matches tokens after stemming and case-folding — “migrating” finds “migrations,” “OAuth” finds “oauth.” It does not find:
- “auth” → “OIDC” / “SSO”
- “slow” → “latency” / “p99”
- “DB upgrade” → “Postgres major version bump”
That’s semantic search, and it’s a different kind of upgrade — embedding model, vector column (sqlite-vec is a loadable extension, stays in the same .db file), hybrid scoring blending BM25 with cosine similarity. Bigger lift — model dependency, embedding cost at index time. Worth it at 500+ notes. Some day.
Eight parts in. Where the stack ended up:
markdown + frontmatter notes — the source of truth
git authorship, history, review
gh auth, install, distribution
github actions the curator
claude code skills /memorize · /recall
sqlite (stdlib) + fts5 retrieval, ranked
grep fallbackNot in there: vector DB, embedding pipeline, sync daemon, hosting service, web UI, search API, onboarding flow.
The infrastructure list barely grew across eight parts. The conventions list did — _taxonomy.md (controlled vocab for tags, repos, services), _conventions.md (note structure rules), the curator’s review checklist (what the GHA bot enforces on every PR), the boost ordering above. That’s where the smarts went.
If BM25 breaks, embeddings. If embeddings break, who knows. Vault stays markdown either way.