
Every AI coding agent session starts from scratch. Your teammate spent 10–15 minutes (and a bunch of tokens) teaching Claude Code about your deployment patterns yesterday. Today you open a new session and it has no idea. All that context just evaporated.
This has been bugging me. We just had our hackathon at Apella (always a good time — extra good when you get to build something you actually want to exist) and I used it as an excuse to take a real stab at this.
The short version: I built a shared persistent memory system for Claude Code. Not individual memory — organizational. The kind where one engineer’s session teaches every future session across the team. Markdown files in a Git repo, two custom skills, no vector DB, no infra beyond what every dev already has installed.
End of session → distill what you learned into a structured note. Start of session → pull in what’s relevant to your current work. Knowledge compounds instead of disappearing.
Sounds nice in theory. So I ran 118 controlled experiments to find out.
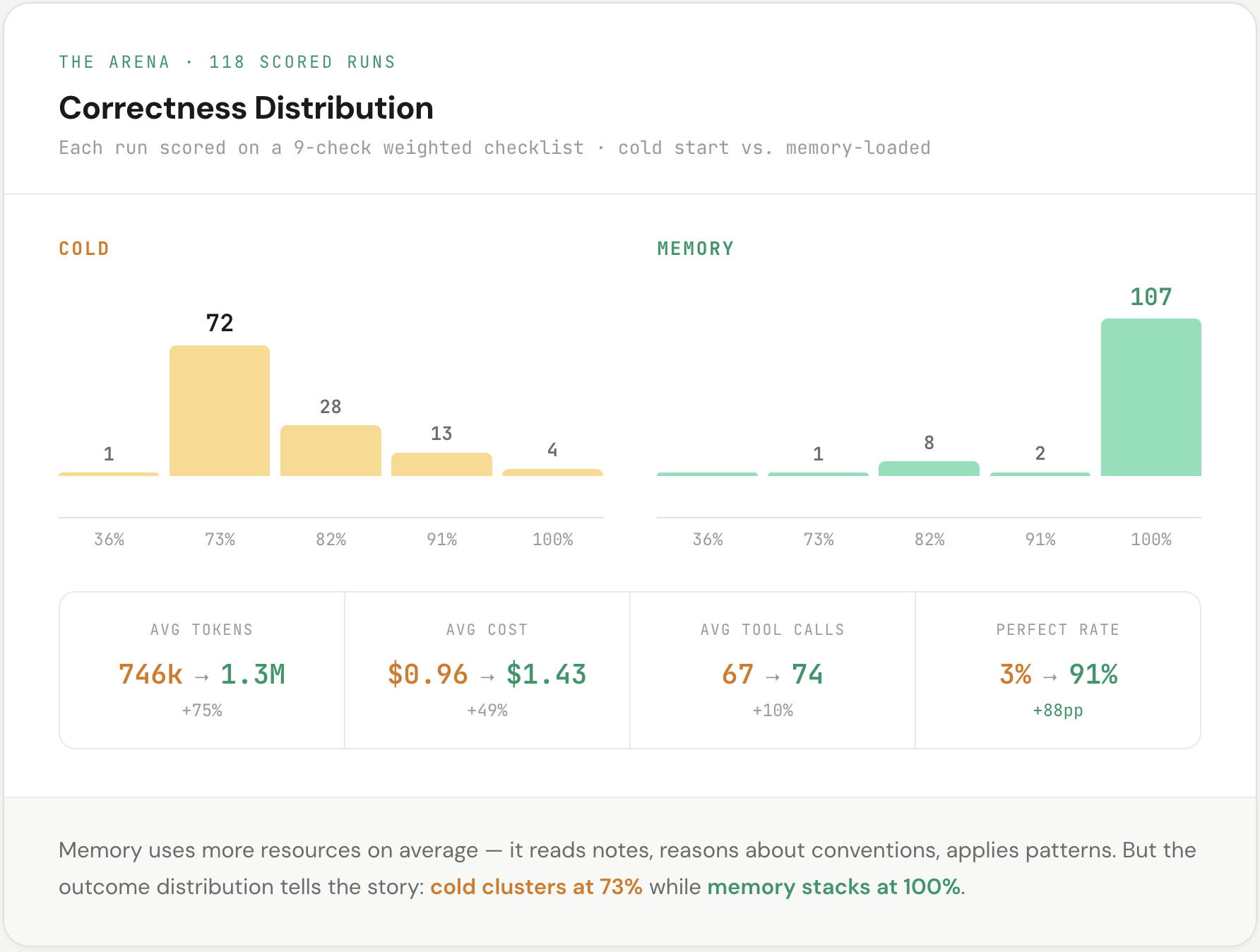
Same coding task, two Claude Code agents running in parallel. One cold start, one with memory loaded. Both scored against a weighted correctness checklist — not vibes, actual pass/fail checks on things the output needs to get right.
Cold: 77.7% correctness. 4 perfect scores out of 118. Memory: 98.4% correctness. 107 perfect scores out of 118.
Both agents ace the straightforward stuff — file creation, right libraries, CI config. Near 100% either way. The entire gap is what I’m calling tribal knowledge. Patterns that live in your team’s head but nowhere in the codebase. Things you’d drop in Slack but never think to put in a README. One check went from a 3% pass rate to 95%.
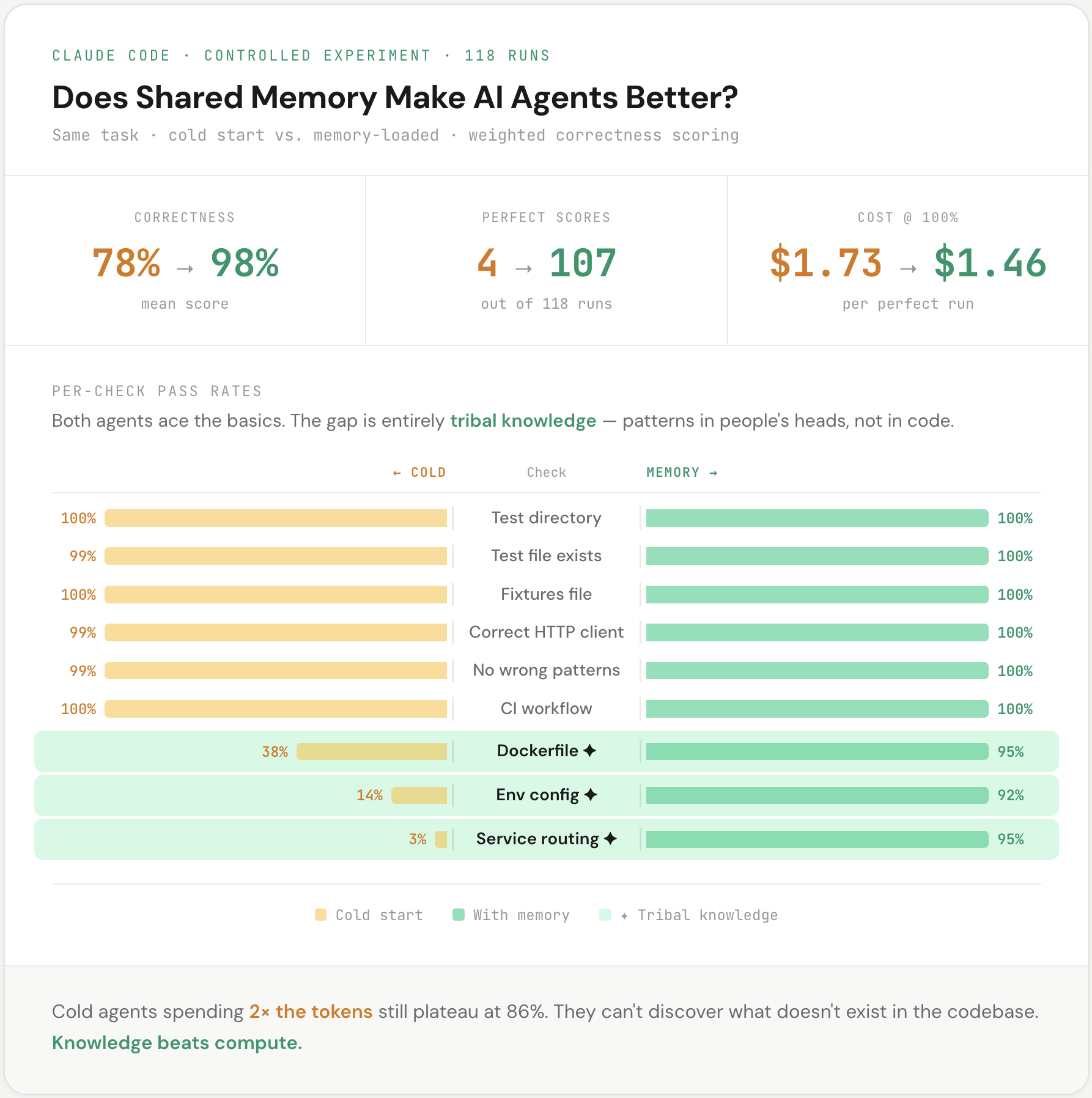
Cold agents that throw 2x the tokens at the problem still plateau at ~86%. They can’t discover what doesn’t exist in the code. And when you filter to only perfect runs, memory is actually cheaper ($1.46 vs $1.73). You literally cannot brute-force institutional knowledge. But you can write it down.
Hackathon project. Sticks and stones. 118 runs later I’m convinced the mechanism works. The question isn’t “does giving an agent context help” — obviously. It’s what happens when every session your team runs deposits knowledge for the next one.
More soon. Turns out writing the notes is only half the problem.