Part 2 of a series on giving AI coding agents shared organizational memory. Previously: Part 1 — Your AI coding agent has amnesia.
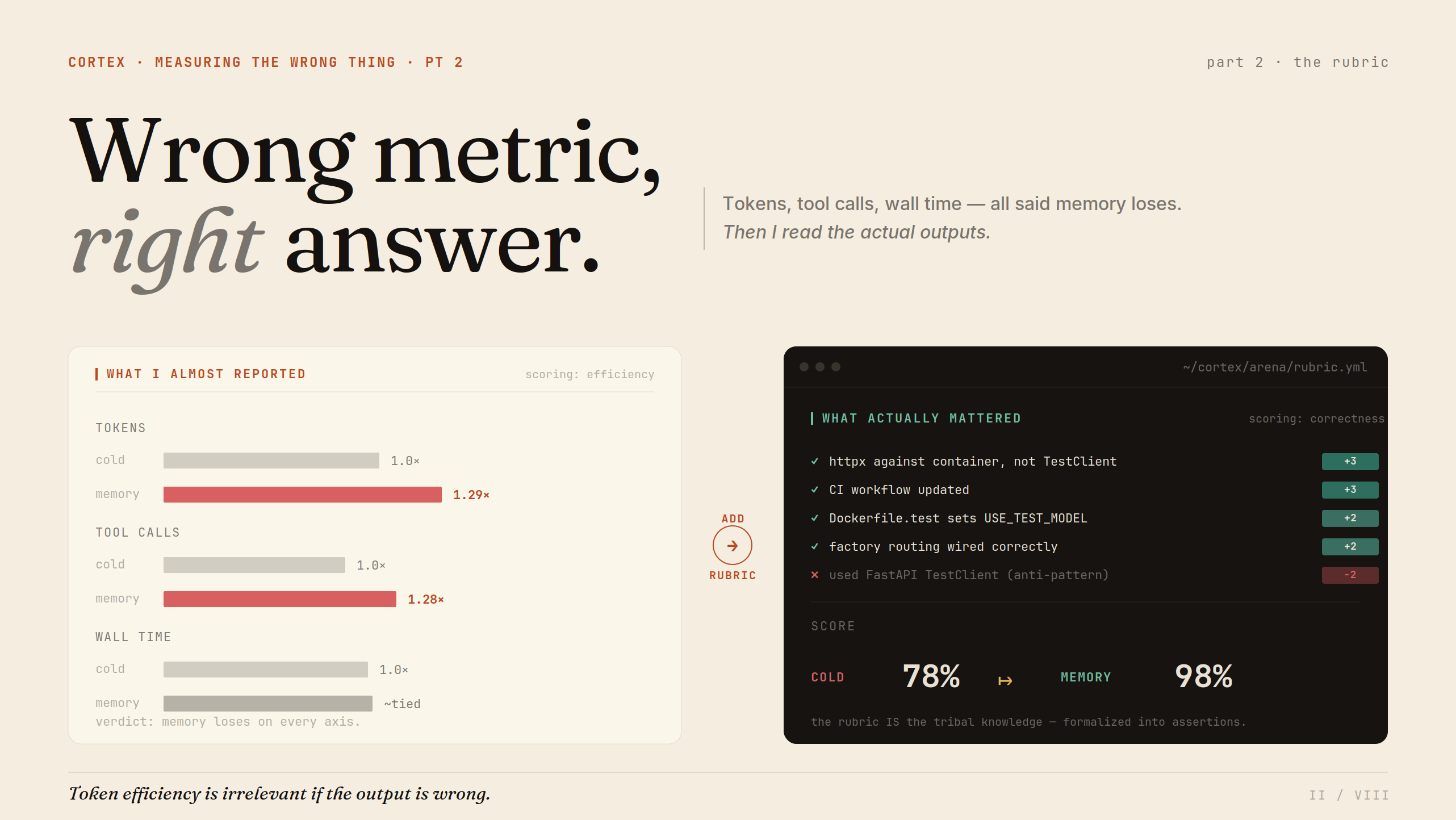
Last week I shared the results of giving Claude Code a shared memory system. Big numbers, clean charts. But I almost reported completely different metrics that would have told the wrong story.
My original hypothesis was simple: give an agent knowledge upfront and it should use fewer tokens, make fewer tool calls, finish faster. Less wandering, more building.
So I built a test harness called the Arena: two Claude Code agents, same task, same prompt, same codebase (git worktree). One starts cold, one gets vault notes. Both run in parallel, everything logged: tool calls, tokens, timestamps, costs.
The first few runs came back with unexpected outcomes. Memory agent used more tokens. More tool calls. Roughly the same wall time. Cool, so my idea doesn’t work?
But I opened the actual outputs. The cold agent wrote integration tests using FastAPI’s TestClient. Our codebase uses httpx against a running container. Skipped the Dockerfile. Didn’t touch factory routing. Didn’t set the test model env var. It got the low-hanging fruit right and phoned in everything that required actually knowing how we do things.
That’s when I realized token efficiency is irrelevant if the output is wrong. I needed a scoring rubric.
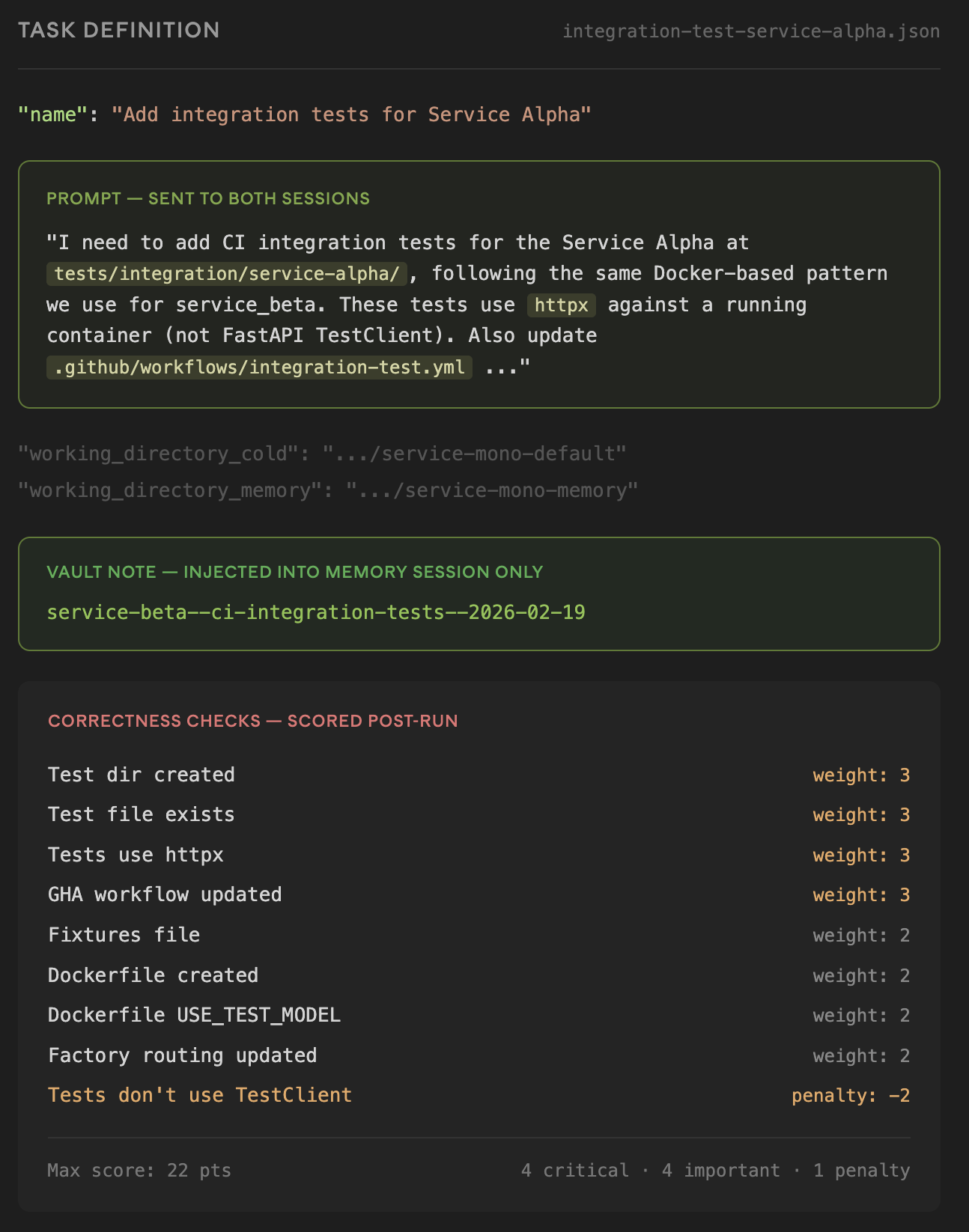
So I redesigned the experiment. Each task gets a weighted correctness checklist: concrete pass/fail checks against the files the agent actually produced. Critical checks (right HTTP client, CI workflow) get weight 3. Important ones (Dockerfile, routing) get weight 2. Anti-patterns get negative weight of -2. Designing these checks took more time than building the harness itself, because the checks basically are the tribal knowledge, formalized into assertions.
With scoring in place, the picture flipped. Memory agents: 98% correctness. Cold agents: 78%. The gap is entirely in checks that depend on institutional knowledge. On the basics — test directory exists, fixtures present, CI config updated — both agents nail it at 99–100%.
The thing that surprised me most: cold agents spending 2x the tokens still plateau around 86%. They explore more, read more, grep harder. But they can’t discover conventions that were never written down. No amount of compute substitutes for knowledge.
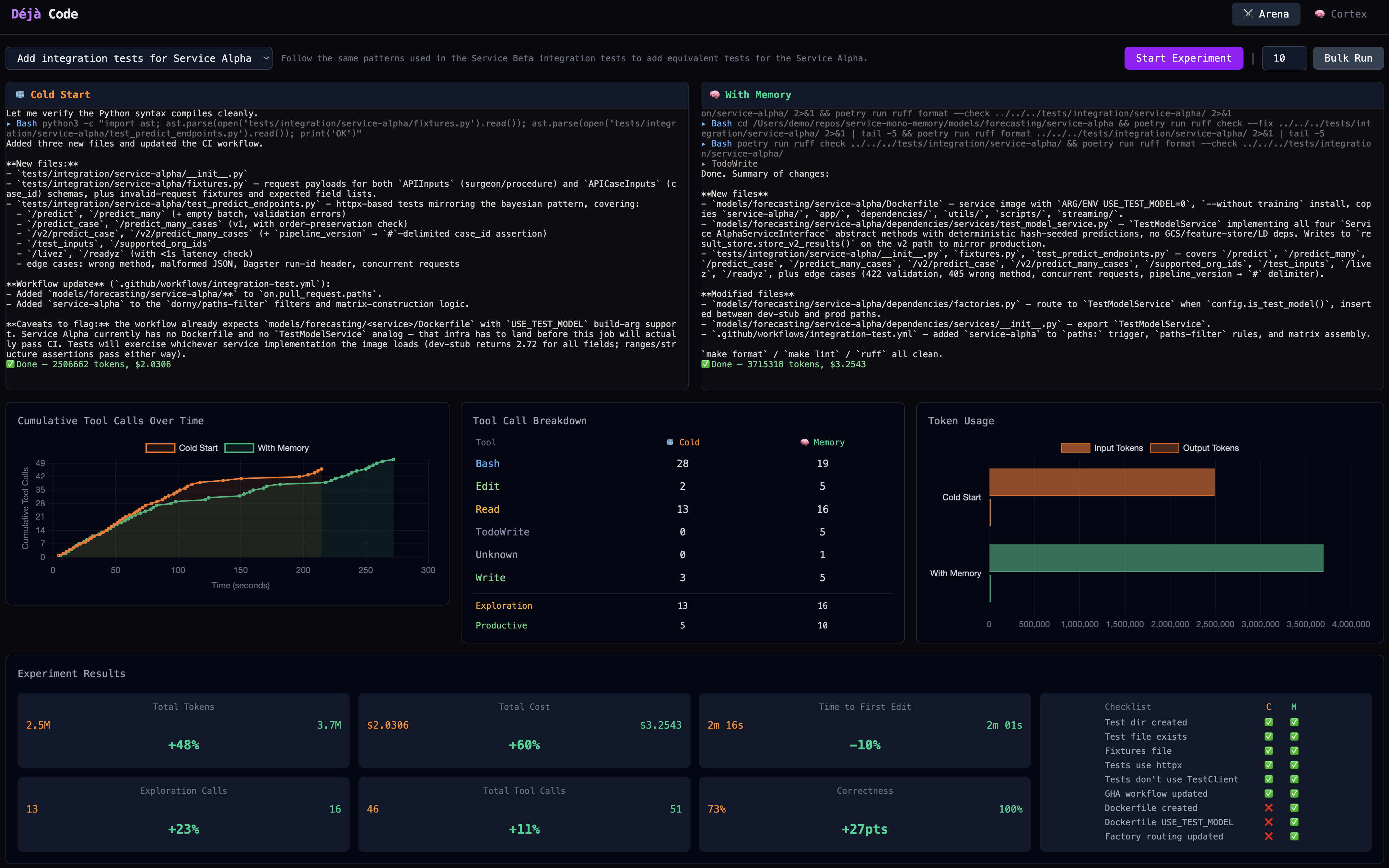
Why 118 runs? Honestly, 18 of those were me tuning the harness, fixing the scoring, and debugging the bulk-run pipeline. The real experiment is 100 controlled pairs. But “I ran 100 experiments” sounds like a round number I made up, and 118 sounds like a guy who kept going until his API budget ran out. Which is also true. Thanks Apella for covering the bill on that one.
If I’d shipped the original metrics I would have concluded memory doesn’t help much. The experiment design mattered more than the experiment. I think about this whenever I see benchmarks for AI tools — what exactly are you measuring, and does it capture what actually matters?