Part 7 of a series on giving AI coding agents shared organizational memory. Previously: Part 1 — Your AI coding agents have amnesia · Part 2 — I was measuring the wrong thing · Part 3 — No vector DB. No embeddings. No RAG. · Part 4 — Knowledge, not logs · Part 5 — /memorize and /recall · Part 6 — If you have
ghyou’re in
Notes go wrong two ways. Either someone writes them wrong. Or someone wrote them right and the world moved on.
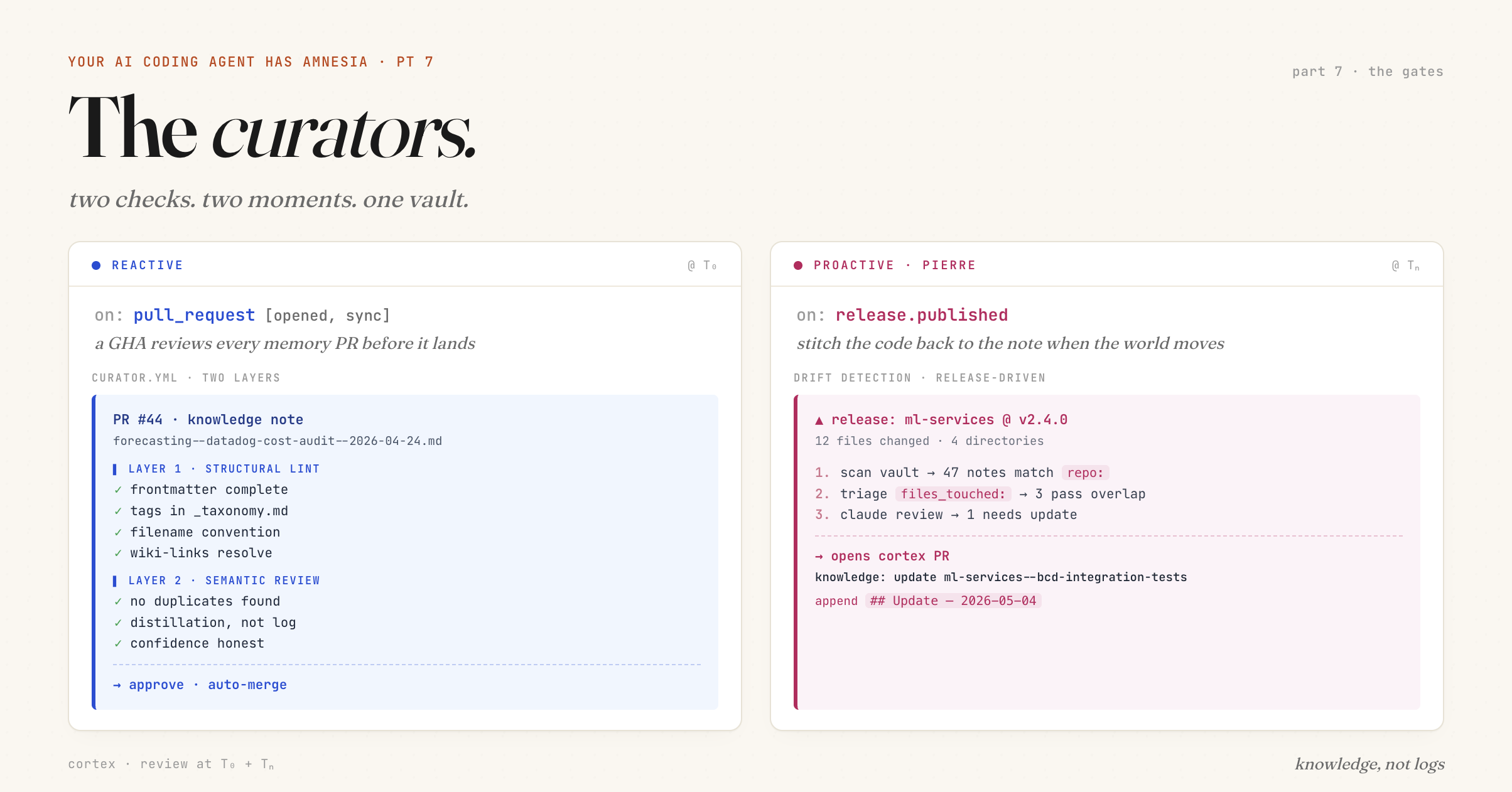
Two curators, one for each. A reactive GitHub Action that reviews every memory PR. And Pierre, our release-documentation bot, quietly catching drift when code moves and notes don’t.
Both feed the same vault. Both go through PR review. The vault stays honest because being right once isn’t enough.
/memorize had to change
Before any of this, /memorize had a quiet behavior: commit and push to main. Fine for one engineer in a hackathon. Wrong for a shared vault.
One-line change in step 5 of the skill. /memorize now creates a branch, commits, opens a PR. Every memory note goes through review. Engineers don’t write to main directly. Pierre doesn’t either. The vault’s history is a sequence of merged PRs, every one of them seen by both a human and a curator.
The reactive curator
A GitHub Action in the cortex repo, triggered on every memory PR. Two layers.
Layer 1: structural lint. A Python script. No LLM. Checks what you don’t need a model for: frontmatter has every required field, every tag exists in _taxonomy.md, confidence is one of high | medium | low, the filename matches {service}--{topic}--{YYYY-MM-DD}.md, every [[wiki-link]] resolves to an existing note.
Most rejections are stupid. A missing tag. A typo in the date. A wiki-link to a renamed note. A script catches those in a second for free. The model never sees them.
Layer 2: semantic review. Claude API call. The new note, _conventions.md, _taxonomy.md, and a manifest of existing notes (filename + title + first line of ## What, not full bodies).
Things a script can’t catch:
- Duplication. Is this substantially the same as an existing note? Should it be an
## Update— appended to that note, not a new file? - Missing links. Obvious
[[wiki-link]]connections the author missed? - Distillation quality. Is this knowledge or did it slip into session-log territory?
- Confidence honesty. Does the body actually support
confidence: high?
Output is structured JSON: approve | suggest | request_changes. Auto-merge, merge with a follow-up issue, or block with a comment. A few cents per PR.
The proactive curator — Pierre
Pierre already existed. When any opted-in Apella repo cuts a release, Pierre reads the diff, updates the docs, opens a PR. He’s been doing this for a while.
Pierre just got a promotion. He detects and corrects vault drift.
The flow on every release:
release.publishedwebhook fires- Pierre scans the cortex vault for notes whose
repo:frontmatter matches the source repo - Triages each match by overlapping the release diff against the note’s
files_touched:. Exact file match, directory prefix, or services-only fallback - For notes that pass triage, Pierre fetches the diff scoped to the overlapping files, sends it to Claude with the note body and the conventions: does this release affect the truth of this note?
- If yes, Pierre opens a PR appending a
## Update — YYYY-MM-DDsection. If no, records the outcome and moves on.
The triage step runs in milliseconds because the notes are structured. repo: and files_touched: are required frontmatter. Pierre doesn’t have to read every note to know which ones a release might affect. Most releases trigger zero Claude calls. The fields are doing the job.
Notes update, not accumulate. The rule in _conventions.md is: never rewrite, only append. The original note stays. The update sits below it, dated. Anyone reading the file sees what was true on day one and what changed since. Git blame works. The history is the document.
Pierre’s drift PR gets labeled documentation, automated, drift-review, then goes through the reactive curator. Same lint, same semantic review. The bot gets the same gate as the engineer.
Two checks, two moments
The reactive curator runs at T₀. Note birth. It evaluates the note against the vault. Conventions, taxonomy, duplicates, distillation. Does this note fit the vault as it stands?
Pierre’s drift detection runs at Tₙ. Release time. It evaluates the note against the world. Diff overlap, file changes, whether the meaning still holds. Does this note still fit the world?
Same evaluation, two moments. Both are necessary because between T₀ and Tₙ the world keeps moving. An engineer runs /memorize mid-PR. Then review feedback comes in. A function gets renamed. A file moves. Follow-up PRs land. By merge, the note is already a little wrong. By release, more.
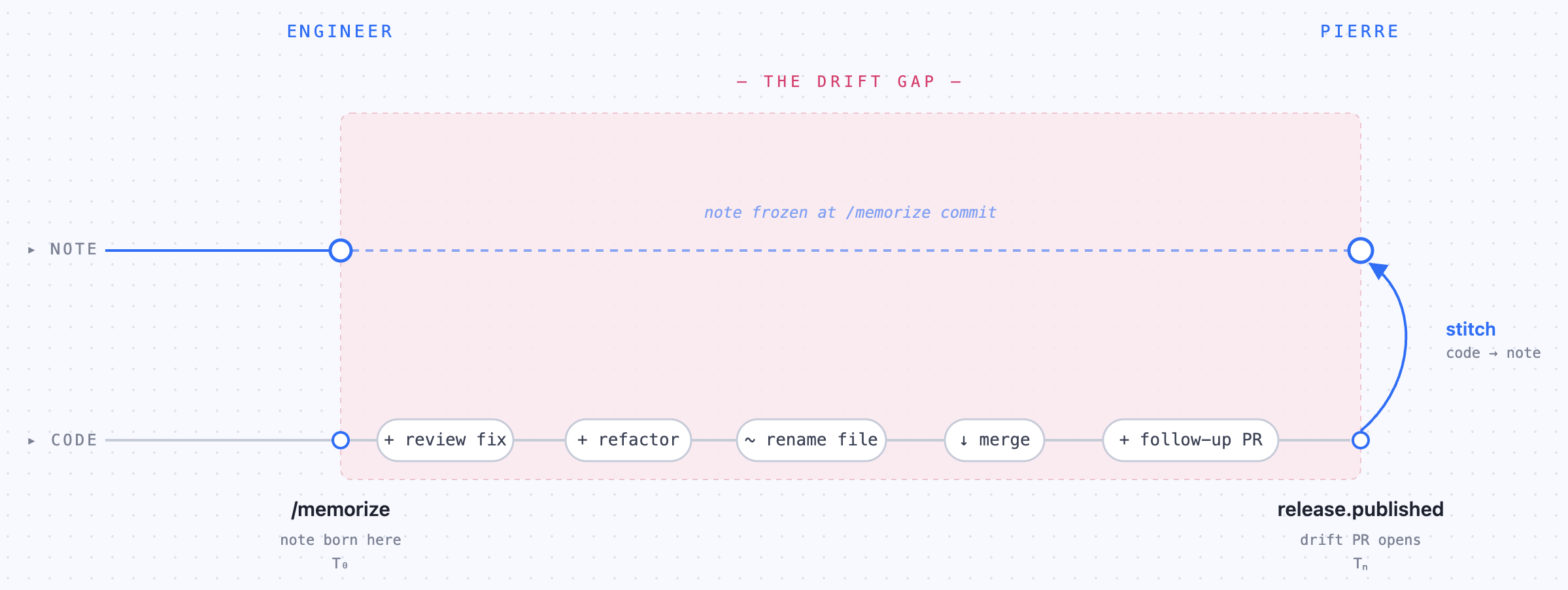
The cleaner architectural version is one service that owns both checks. Pierre handles reactive review and proactive drift. Same model, same conventions, same idea of fit. Tempting on paper. But the reactive curator is self-contained: a GHA living in the cortex repo with no external dependency, that runs even if Pierre is down. That’s worth a duplicate prompt.
Two Claude calls because there are two moments. The design isn’t a bug to consolidate away.
The thing that kills wikis is logs. Sessions get dumped in. Distillation slips. Every entry decays at a different rate. Search degrades. Two curators is how “knowledge, not logs” survives contact with a real team.
One catches bad writing on the way in. The other catches good writing that went stale. Both feed the same vault. Both end as merge or request-changes.
Next post: when grep stops working.