Part 4 of a series on giving AI coding agents shared organizational memory. Previously: Part 1 — Your AI coding agent has amnesia · Part 2 — I was measuring the wrong thing · Part 3 — No vector DB. No embeddings. No RAG..
The whole system is two files and a note template.
_taxonomy.md defines what tags exist. _conventions.md defines how notes are written. Together under 300 lines. Every /memorize and /recall loads both before doing anything. Every curator review checks new notes against both. That’s the constitution.
Sounds thin. Is thin. All the “intelligence” people expect in a memory system — ranking, semantic similarity, dedup, relevance — got pushed into two markdown files telling agents what to write and how to find it. Prompt engineering as infrastructure.
_taxonomy.md — the tag schema
Five dimensions: service/, tool/, pattern/, team/, domain/. Every note picks tags from multiple categories at once. A note on migrating inference training to Dagster Pipes gets service/inference, tool/dagster, pattern/migration. All three. Not a hierarchy. A grid.
Why multi-dimensional. Organize by folders and you pick one axis, the rest go second-class. An engineer asking “how do we do migrations” gets blocked by a structure built for “which service does this belong to.” Flat tags remove the choice.
The file is also a social artifact. Need a new tag, open a PR with a one-line definition. Takes 30 seconds. Reviewer agrees or points at an existing one. Vocabulary drift gets caught in one place, before it spreads. Not via tooling. Because the definitions are in one place and the diff is readable.
_conventions.md — the writing rules
Five principles, roughly in order of how much work they do:
- Knowledge, not logs. Decisions, gotchas, patterns, architecture. Not session transcripts. Write for a colleague who wasn’t there.
- Link, don’t duplicate. If something’s already explained in another note, reference it with
[[note-name]]. Vault should converge, not sprawl. - Frontmatter is the search index. Accurate tags, services, file paths are what make retrieval work. Garbage in, garbage out.
- Short beats long. A 40-line note with clear decisions beats a 200-line brain dump.
- Update over create. If a note exists and your work extends it, update it. New notes only when the topic is genuinely different.
Plus the filename: {service}--{topic}--{YYYY-MM-DD}.md. Filename alone tells you if a note’s relevant before you open it. ls memory/ is half the search.
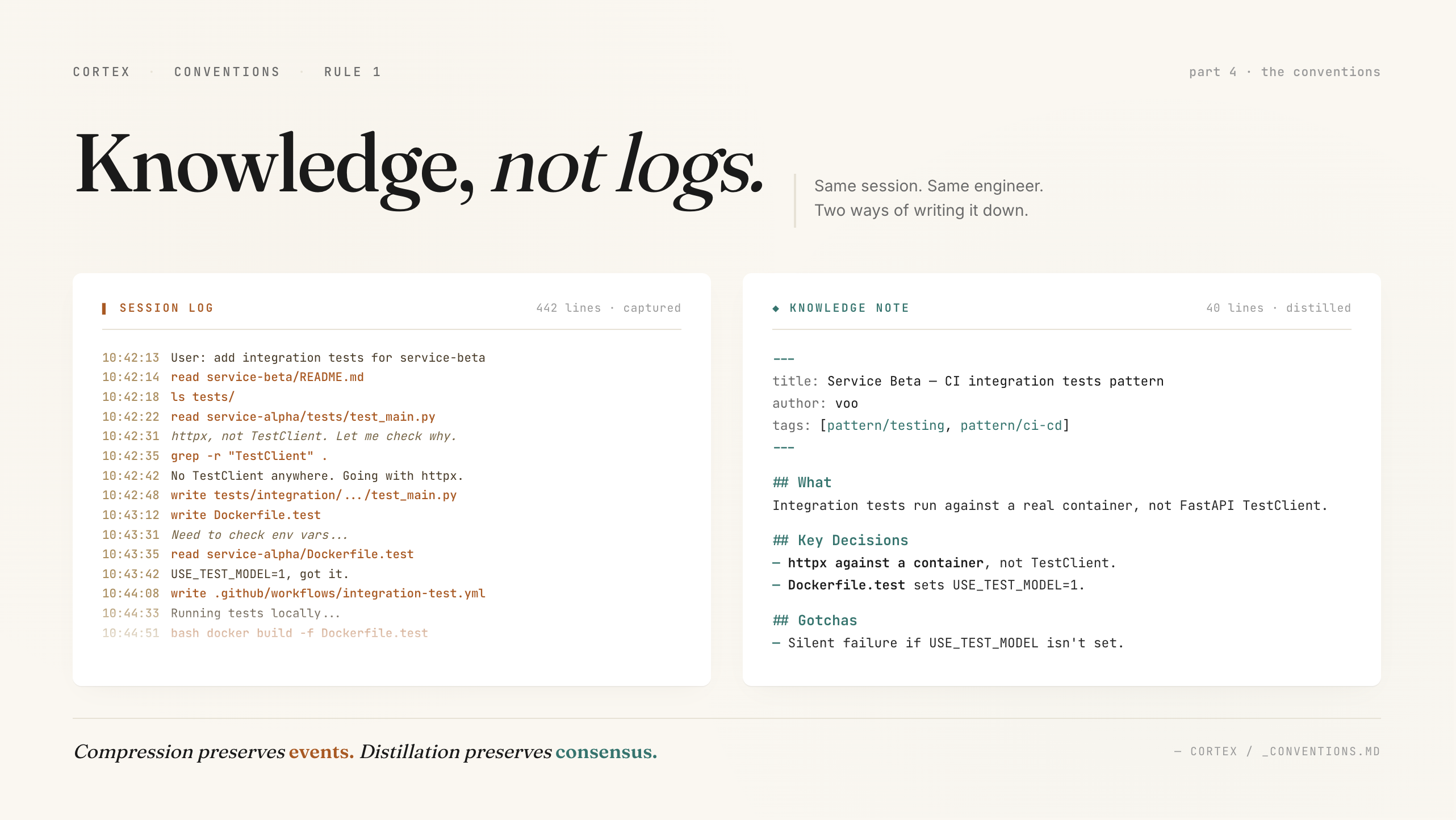
Rule 1 does the most work. Agents love to log. Ask an agent to “remember this session” and you get a blow-by-blow — what was tried, what failed, what finally worked. Rule 1 forces distillation. What would someone who wasn’t there need to know? That’s the note.
Rule 2 keeps grep viable as the vault grows. No duplicates, fewer false positives per query. Wiki-links also give you the graph for free. grep -r '\[\[' memory/ and you’re done.
Rule 3 is the concession to how retrieval actually works. No embeddings, no soft matches on meaning. Forget to tag a note tool/dagster, and the agent searching for Dagster issues isn’t finding it. Frontmatter is the contract.
Anatomy of a note
One real one. The note actually injected in Part 2’s memory arm — the CI integration tests pattern for Service Beta:
---
title: Service Beta — CI integration tests pattern
repo: service-beta
services: [service-beta]
author: voo
date: 2026-02-19
tags: [service/service-beta, tool/docker, tool/github, pattern/testing, pattern/ci-cd]
files_touched:
- tests/integration/
- Dockerfile.test
- .github/workflows/integration-test.yml
confidence: high
---
## What
Integration tests run against a real container, not FastAPI TestClient.
Dockerfile.test sets `USE_TEST_MODEL=1` so the container wires to the test
model factory. GHA spins up the container and hits it with httpx.
## Key Decisions
- **httpx against a container**, not TestClient. TestClient skips middleware
and env-dependent routing. Got burned on both in prod.
- **Dockerfile.test separate from prod Dockerfile**. Test image sets env flags
that would be dangerous on the prod image.
- **Factory routing gated on `USE_TEST_MODEL`**. Request goes through the
same path as prod. Factory returns the test model.
## Gotchas
- If `USE_TEST_MODEL` isn't set in the Dockerfile, tests pass locally but
route to the real model in CI. Silent failure.
- `httpx` and `requests` differ on redirect handling. We standardized on httpx.
## Related
- [[service-alpha--ci-integration-tests--2026-04-12]] — Alpha adopted this
- `tests/integration/service-beta/README.md`Frontmatter on top, machine-readable. A simple grep pulls every note touching a service. grep -l "pattern/testing" memory/ | xargs grep -l httpx narrows to testing notes mentioning httpx. That’s the retrieval layer.
Body below. Four sections — What, Key Decisions, Gotchas, Related. Not mandatory. These are the sections that kept showing up because they’re the questions engineers actually ask. What’s this about. What choices got made. What’s going to bite me. What else should I read.
Note is 40 lines. Took the author five minutes. Saves the next engineer an hour of confusion about why TestClient “isn’t good enough” and why USE_TEST_MODEL exists. That hour is the tribal knowledge gap from Part 1. This note closes it.
Most memory systems put the smarts in the retrieval layer. Better embeddings, better ranking, better semantic matching. Cortex puts them in the authoring layer. The convention file is the smarts. The taxonomy is the schema.
The whole thing is readable. Every rule is in a markdown file a new engineer can read in ten minutes. Every tag is documented in one place. When something’s off, you fix the convention. Not the infrastructure.
Side effect nobody warned me about. Agents are really good at following these rules. Ask Claude Code to distill a session matching _conventions.md; it will. Ask it to use only tags from _taxonomy.md; it will. The friction between humans and documentation conventions mostly doesn’t exist between agents and markdown.
Two files define what a note is. Next post: two skills that do the writing and reading.