Part 6 of a series on giving AI coding agents shared organizational memory. Previously: Part 1 — Your AI coding agents have amnesia · Part 2 — I was measuring the wrong thing · Part 3 — No vector DB. No embeddings. No RAG. · Part 4 — Knowledge, not logs · Part 5 — /memorize and /recall
The architecture means nothing if nobody installs it.
I waved past this in Part 3. Adoption is a one-way ratchet — you don’t get a second install. The first version of Cortex needed a clone, an env var, and skill files copied into your .claude/ dir on every machine. The architecture was right. The install was killing it.
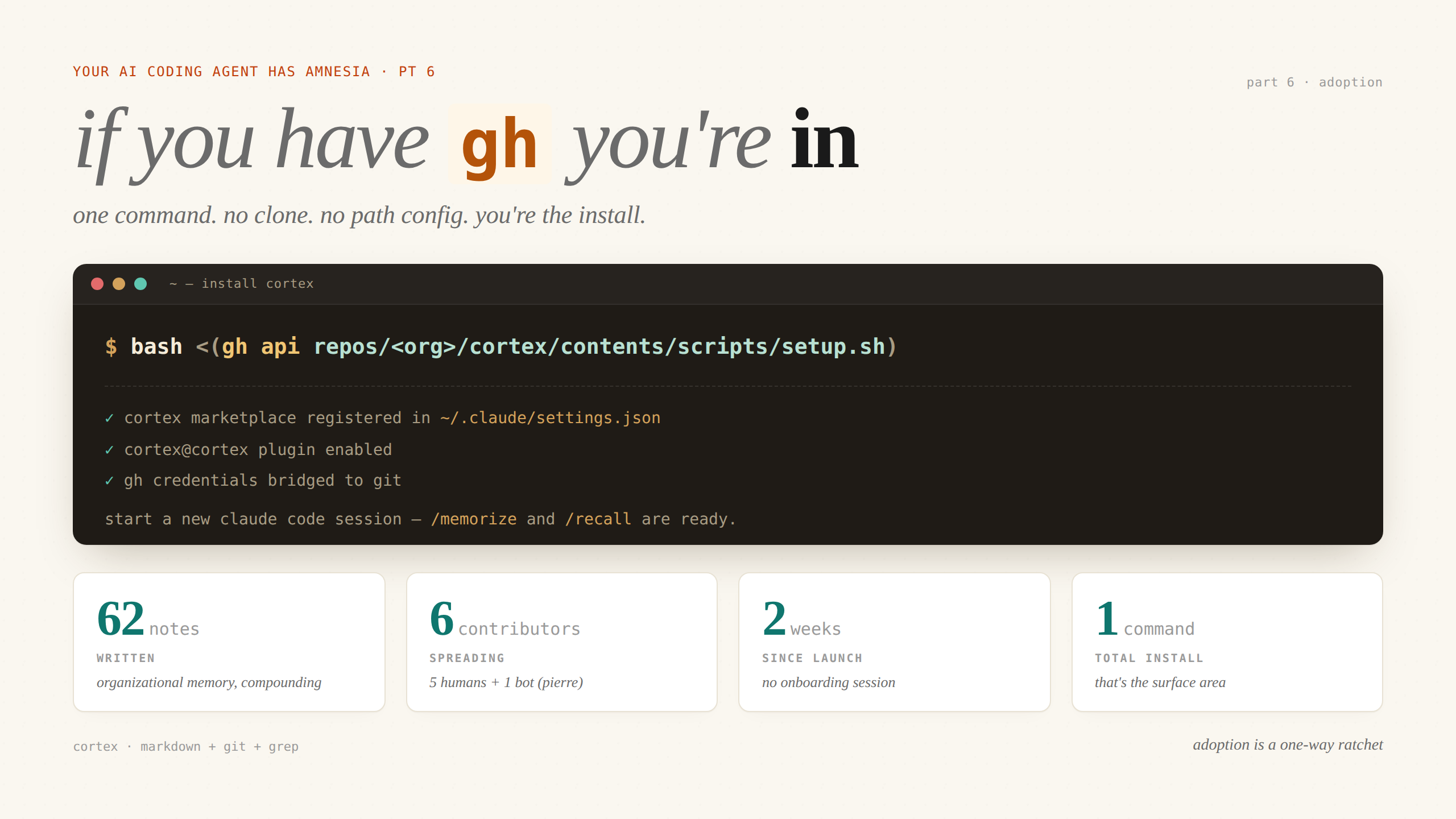
Cortex ships as a Claude Code plugin now. One command, sketched (not literal — internal repo, internal install):
bash <(gh api repos/<org>/cortex/contents/scripts/setup.sh)That’s it. No clone. No env var. No path config. Next session, /memorize and /recall work in every repo on your machine.
Why gh
Apella is a GitHub shop. Every engineer already has gh authenticated — it’s how they clone, PR, and review. Piggybacking on gh auth means I don’t ship another credential dance. The script also runs gh auth setup-git so the background git clone of the plugin doesn’t trigger an interactive password prompt inside Claude Code.
I learned that one the painful way. An interactive prompt inside a Claude Code session has nowhere to go — no input field, no escape. The session is dead. gh auth setup-git is the difference between a working install and a brick.
The gh api call pulls the setup script from the private repo using the user’s existing token. No public mirror. No curl-from-pastebin. If you have read access, you have install. If you don’t, you don’t.
What the one command actually does
Three things:
- Registers the cortex marketplace in your Claude Code user settings (
~/.claude/settings.json) - Enables the cortex plugin in that marketplace
- Bridges
ghcredentials to git so private cloning works silently
That’s the install. Everything else is Claude Code’s plugin runtime:
- On next session start, Claude Code clones the plugin from the marketplace
- The plugin’s
SessionStarthook auto-clones the vault to a managed path under~/.claude/— engineers never touch it - Skills get registered as
/memorizeand/recall - Every subsequent session pulls latest vault before any agent runs — cheap on a fresh clone, near-free on a fast-forward. Git’s job, not mine.
That last one is the part that compounds. Notes a teammate wrote yesterday land in my /recall results today. Without me doing anything. The vault is a moving target by design and the plugin keeps you on the latest commit.
Adoption, two weeks in
62 notes. 6 contributors — 5 humans, 1 bot. Spanning ML, data, platform, infra, and web. The bot is Pierre, our release agent. Pierre noticed a service rename in a merged PR didn’t propagate to the relevant memory note and opened a /memorize PR to update it. The service was new to me — I learned it existed from Pierre’s PR. Cortex now has a non-human contributor that catches drift between code and notes I haven’t even read yet. More on that in Part 7.
The human contributor distribution is lopsided, and that’s the part I didn’t expect to land so cleanly. The bulk of the notes came from engineers on other teams — people with no obligation to use this thing, writing into it without being asked. That’s the signal I was actually watching for. A tool nobody installs is dead. A tool people install but nobody writes into is a read-only museum. Notes showing up from teams I don’t sit on means the loop is closing on its own.
Worth restating: Cortex is for agents first, humans second. The notes are markdown — humans can read them, and sometimes do — but the design target is the agent. /recall runs in-session today, on demand. The nice property of markdown is that the same artifact serves both readers. The agent is the primary consumer. The human is the writer, the curator, and an occasional grateful beneficiary.
What’s not in the stack
No web UI. No login flow. No search endpoint. No sync daemon. No vault hosting service. No onboarding wizard. No Slack bot. No dashboard.
Claude Code is the client. GitHub is the backend. The plugin is markdown and bash. Total surface area is small enough that one engineer can keep it in their head, which means the bug rate scales with how much I touch the code, not how many people use it.
Install was the second invisible problem. The first was what to write down — Parts 4 and 5. The third is what to do when people/agents write the wrong things.
Coming up: the curators.